Sometimes you need to have access to a website’s data while offline. Maybe you’d like a backup of your own website but your hosting service doesn’t have an option to do so. It may be the case that you’d like to imitate how a popular website is structured or what their CSS/HTML files look like. Whatever the case there are a few ways you can download a part of or a complete website for offline access.
Some websites are too good to simply linger online that’s why we’ve gathered 8 awesome tools which you can use to easily download any website right to your local PC. This something similar to our guide about backing up your Twitter account.
The programs we mention below can serve this purpose very well to download an entire website for offline use. The options these apps present are straightforward and you can begin downloading an entire website in just a couple of minutes.
Download Partial or Complete Website for Offline Access
1. HTTrack

HTTrack is an extremely popular program for downloading websites. Although the interface isn’t quite modern, it functions very well for its intended purpose. The wizard is easy to use and will follow you through settings that define where the website should be saved and some specifics like what files should be avoided in the download.
For example, exclude whole links from the site if you have no reason to extract those portions.
Also, specify how many concurrent connections should be opened for downloading the pages. These are all available from the “Set options” button during the wizard:

If a particular file is taking too long to download, you can easily skip it or cancel the process midway.

When the files have been downloaded, you can open the website at its root using a file similar to this one here, which is “index.html.”

2. Getleft

Getleft has a new, modern feel to its interface. Upon launch, press “Ctrl + U” to quickly get started by entering an URL and save directory. Before the download begins, you’ll be asked which files should be downloaded.
We are using Google as our example, so these pages should look familiar. Every page that’s included in the download will be extracted, which means every file from those particular pages will be downloaded.

Once begun, all files will be pulled to the local system like so:

When complete, you can browse the website offline by opening the main index file.

When complete, you can open the download and view it offline, like this:
3. Cyotek WebCopy

Use predefined passwords for authentication and create rules with Cyotek WebCopy to download a full site for offline viewing. Start a copy of the “F5” key and watch as the files are downloaded.
The total size of the currently downloaded files shows in the bottom right corner of the window.

You can even create a web diagram for a visual representation of the files.

4. Wikipedia Dumps

Wikipedia doesn’t advise users to use programs like those above to download from their site. Instead, they have Dumps we can download here. For example, here are dumps for October 28th, 2013:

Download these clumps of data in XML format, extracting them with something like 7-Zip.
5. SiteSucker
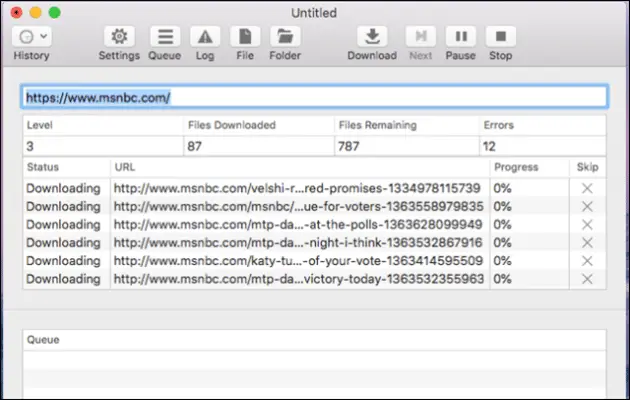
If you are a Mac user, this one can be a good option to download an entire website for offline viewing. It does everything by asynchronously copying the site’s web pages, PDFs, images, style sheets and other files to your local drive.
The process to download a complete website cannot get easier than this where you simply have to enter a URL and press return, and you get all the website’s content right on your computer.
You can also use SiteSucker to make local copies of websites. It has its online manual that explains all the features. SiteSucker localizes the files it downloads that allows you to browse a site offline.
How to use SiteSucker to download an entire website for offline view
- Input the site name
- Select the download folder if needed.
- Click Download and it starts its magic.
6. Web2Disk Downloader
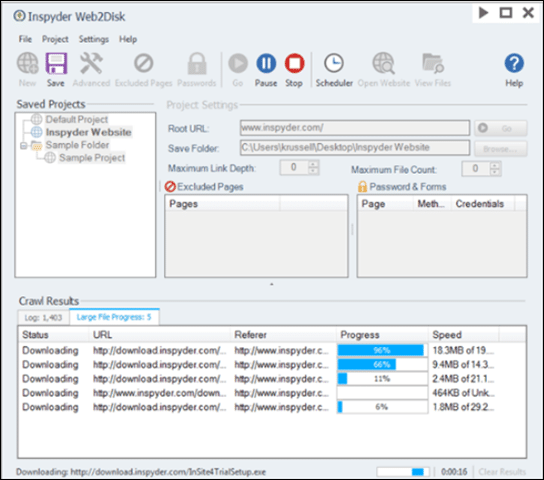
Web2Disk Downloader is the answer to the question: how to download an entire website to your PC quickly and easily? It comes with all the nifty features to get your task done. It comes with a powerful engine that allows it to modify websites as they are downloaded that ultimately makes all the links work directly from the hard drive of the computer.
You can view the downloaded websites in any browser. It comes with no page limits, no site limits so that download as many websites as you want. You just have to buy it once and use it forever. It also has a “Scheduler” feature that automatically downloads and archives the sites, daily, weekly or monthly.
How to use Web2Disk to download an entire website
Install the program and run it. Now enter the URL of the website that you want to download, and the name of the new project.
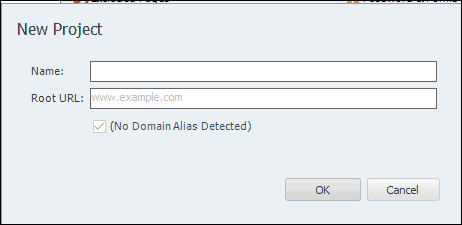
You can save the whole content wherever you want in your PC. Browse the file path to set your preferred location. Now, click on Go.
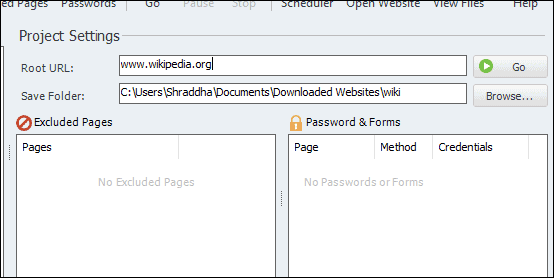
Let the process to be completed.
Once done, you will see a message at left bottom as Download completed.
7. Offline Downloader
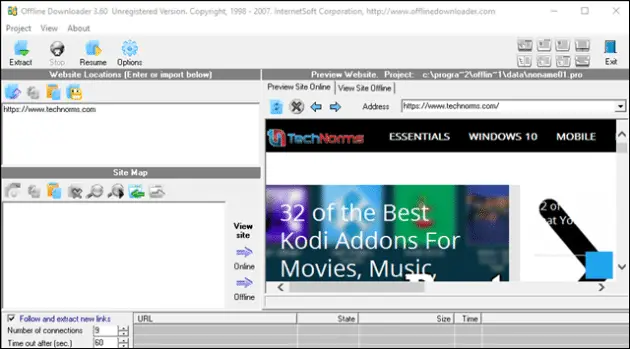
Offline Downloader lets you download n number of websites where you do not need to click your mouse a hundred times while saving files in your directory. The downloaded web links can be renamed to relative local files that allows you to move information easily to CD-ROM or any other drive.
It allows you to make an exact copy of any website on your hard drive. Viewing sites with photo albums or galleries is easy, and various types of graphics files are readable like JPG and GIF files.
You may not be able to open it from the Windows Search bar until you are logged as an Admin. Otherwise, the second option is that you create a desktop shortcut by going into the Offline Downloader file’s location.
Sometimes you do not need the entire content of the website, but just some specific data. In such cases, using a web scraper is a better idea. A tool like ProWebScraper can help you scrape pricing, contact details or other data off your target webpages
Conclusion
Among the listed programs, I’ll say with confidence you’ll be able to download any website you want. Whether authentication is required or you only want select pages to be extracted, one of the above freeware programs will surely do.
The Wikipedia is a great resource for offline access. Studying about a topic or just want to read up on a specific topic? Download the data from the Wikipedia dumps and access it offline anytime you want.
Bonus tip: If you like the idea of accessing websites offline you may like to read about using Gmail without an internet connection with the Gmail Offline Extension.





